
Getting data out of MySQL shouldn’t require a data engineering degree. Yet most teams waste hours wrangling exports, fighting with connectors, or building brittle scripts that break every time schemas change.
This guide covers 9 MySQL ETL tools for 2026. Each serves different needs—from spreadsheet-first reporting to enterprise-scale CDC pipelines. Find the right fit for your technical skill level, budget, and use case.
Quick Decision Guide
Start here. Answer these questions to narrow your options:
| If you need… | Consider… |
|---|---|
| MySQL → Sheets/Excel with no-code setup | Coefficient |
| Fully managed CDC with minimal maintenance | Fivetran |
| Open-source flexibility + MySQL as source/destination | Airbyte |
| Low-code platform with reverse ETL | Integrate.io |
| Large-scale distributed processing | Apache Spark |
| On-prem ETL with visual job design | Talend Open Studio |
| No-code real-time sync for startups | Hevo Data |
| Simple warehouse ELT with predictable pricing | Stitch Data |
| SQL-heavy warehouse transformations | Matillion |
MySQL ETL Tools: Feature Comparison
| Tool | Type | Deployment | Best MySQL Sync Mode | Real-Time | 2026 Pricing Model |
|---|---|---|---|---|---|
| Coefficient | ELT | Cloud | Query-based incremental | Near-real-time | Per-user |
| Fivetran | ELT | Cloud | Log-based CDC | Near-real-time | MAR-based |
| Airbyte | ETL/ELT | Cloud + Self-hosted | CDC + Full/Incremental | Near-real-time | Usage-based or Free (self-hosted) |
| Integrate.io | ETL/ELT/Reverse | Cloud | Full + Incremental | Near-real-time | Subscription tiers |
| Apache Spark | ETL/ELT | Self-hosted + Managed | Custom (JDBC) | Yes (Streaming) | Infrastructure + Compute |
| Talend Open Studio | ETL | Self-hosted | Batch (Full/Incremental) | No | Free (Open-source) |
| Hevo Data | ETL/ELT | Cloud | CDC + Incremental | Near-real-time | Row-based tiers |
| Stitch Data | ELT | Cloud | Incremental + Log-based | Scheduled batch | Row-based |
| Matillion | ELT | Cloud + Self-hosted | Batch (Query/Key-based) | Scheduled | Credit-based |
#1 Coefficient

Type: ELT | Deployment: Cloud
Best for: Business users who want MySQL data in Google Sheets or Excel for self-service reporting—without building full pipelines.
Coefficient turns spreadsheets into a lightweight data workspace. Its native MySQL connector lets you run SQL or use a no-code UI to pull live database data into Sheets on a schedule. The focus is operational analytics and lightweight write-back, not heavy-duty orchestration. Ideal for sales, ops, and finance teams that live in Google Workspace or Office.
Unlike traditional ETL platforms, Coefficient keeps you in the tool you already know. Pull MySQL data, set refresh schedules, and even push changes back to the database—all from your spreadsheet.
Key Features
MySQL → Sheets/Excel sync. Run custom SQL queries or import full tables directly into your spreadsheet. No exports, no CSVs, no manual updates.
Auto-refresh schedules. Set hourly, daily, or weekly refreshes. Reports stay live without intervention.
2-way sync. Write updates from Sheets back into MySQL for bulk edits and lightweight workflows.
MySQL Integration Specifics
- Connection method: Native MySQL connector over secure connection (host, port, DB, user, password), configured from the Sheets/Excel add-on.
- Sync modes: Full-table pulls and query-based incremental pulls driven by SQL filters. No log-based CDC.
- Transformation: In-spreadsheet (formulas, pivot tables, joins with other sources). No server-side transformation engine.
- Real-time: Near-real-time via frequent scheduled refreshes. Not sub-second streaming.
Pricing (2026)
Team-oriented pricing. Google Workspace Marketplace listing indicates a commercial SaaS model with per-user pricing and feature limits. Most deployments treat Coefficient as a productivity add-on rather than a primary ETL platform.
- Free tier: Basic features with limited refreshes
- Pro: $29/month per user
- Enterprise: Custom pricing
Pros
- Very low friction for non-engineers already working in Sheets/Excel
- Fast time-to-value for MySQL reporting and simple operational workflows
- 2-way sync covers many “light ETL” update scenarios without engineering tickets
Cons
- Not suited for complex, multi-hop pipelines or large-scale warehouse ETL
- Lacks advanced orchestration, testing, and CI/CD features data teams expect
- No log-based CDC; high-frequency syncs on large tables can stress MySQL
Ideal for: SMB to mid-market teams with limited data engineering resources that need MySQL → Sheets/Excel analytics and lightweight write-back.
Not ideal for: Central data platforms needing robust CDC, data quality, and cross-environment orchestration into warehouses or lakes.
Ready to pull MySQL data into your spreadsheet? Get started with Coefficient today.
#2 Fivetran
Type: ELT | Deployment: Cloud
Best for: Teams that want fully managed MySQL ingestion into cloud warehouses with minimal maintenance and strong CDC.
Fivetran offers a fully managed MySQL connector that handles extraction, schema drift, and loading into warehouses like Snowflake, BigQuery, and Redshift. Log-based replication provides reliable CDC without heavy full-table reloads. The platform emphasizes zero-maintenance connectors and strong security/compliance—appealing to regulated industries and lean data teams that prefer not to manage ETL infrastructure.
Key Features
Managed MySQL connector. Automatic schema migration handling and error recovery. Set it and forget it.
Log-based CDC. Low-latency incremental syncs without hammering your source database with full-table reloads.
300+ prebuilt connectors. Consolidate SaaS apps, databases, and event streams into a single warehouse alongside MySQL data.
MySQL Integration Specifics
- Connection method: Direct TLS connection, SSH tunnel, AWS PrivateLink, or Proxy Agent with a dedicated MySQL user. MySQL 5.5+ required.
- Sync modes: Initial full-table load, incremental sync via binary logs (CDC), and periodic table re-syncs for edge cases.
- Transformation: Primarily ELT. Transformations run in-warehouse (dbt-style), plus optional Fivetran Transformations.
- Real-time: Near-real-time CDC (minutes-level) depending on plan and configuration.
Pricing (2026)
Usage-based on Monthly Active Rows (MAR):
- Standard: ~$500 per million MAR
- Enterprise: ~$667 per million MAR
- Business Critical: ~$1,067 per million MAR
- Free tier: Available for low-volume use
Note: Discounts apply per connector rather than workspace-wide. Costs can add up in connector-heavy environments.
Pros
- Extremely low operational overhead with robust CDC and automated schema handling
- Strong security options (TLS, SSH, PrivateLink) and enterprise compliance posture
- Broad connector library simplifies consolidating SaaS + MySQL into a single warehouse
Cons
- MAR-based pricing can become expensive at scale or with many connectors
- Limited flexibility compared with open-source frameworks for custom ingestion logic
- No self-hosted runtime; some organizations may not accept external cloud agents
Ideal for: Mid-market and enterprise teams standardizing on a modern warehouse, prioritizing reliability, CDC, and low-maintenance ELT.
Not ideal for: Very cost-sensitive startups, hybrid/on-prem-only environments, or teams that require deeply custom ingestion pipelines.
#3 Airbyte
Type: ETL/ELT (Both) | Deployment: Cloud and Self-hosted
Best for: Engineering and analytics teams that want open-source connectors and flexible MySQL-as-source and MySQL-as-destination pipelines.
Airbyte provides certified MySQL source and destination connectors, supporting batch and CDC replication into or out of MySQL. With 400+ prebuilt sources and many destinations, the open-core model lets teams self-host for full control or use Airbyte Cloud for managed infrastructure. Integrates well with modern transformation tools like dbt.
Key Features
Certified MySQL source connector. Standard and CDC replication methods. Pull data reliably with community-backed connector quality.
MySQL destination connector. Load data from APIs, files, and other databases INTO MySQL. Useful for ELT workflows where MySQL is the target.
400+ prebuilt connectors. Plus 10,000+ custom connectors via extensible SDK. Build what you need.
MySQL Integration Specifics
- Connection method: Standard MySQL credentials (host, port 3306, DB, user, password) with optional SSH tunnel and encryption settings.
- Sync modes: Full refresh, incremental, and CDC using MySQL replication logs, depending on configuration.
- Transformation: Optional. Primarily ELT into the destination, but can integrate with dbt or external transformation steps.
- Real-time: Low-latency via CDC and frequent sync schedules. Not microsecond streaming but close to near-real-time for most workloads.
Pricing (2026)
- Open-source (self-hosted): Free. Only infrastructure costs.
- Airbyte Cloud: Usage-based pricing. Competitive vs Fivetran and Stitch. Exact rates vary by region and volume.
Pros
- Open-source with flexible deployment and connector extensibility
- Strong MySQL support both as source (CDC) and destination (ELT target)
- Cost-effective at moderate scale compared to legacy managed ETL vendors
Cons
- More operational overhead than fully managed offerings when self-hosted
- UI and monitoring less polished than some enterprise incumbents
- Requires engineering ownership to design reliable, production-grade pipelines
Ideal for: Startups to mid-market data teams with engineering capacity that want open-source flexibility and robust MySQL integration.
Not ideal for: Non-technical teams needing a turnkey, fully managed, no-ops ELT with enterprise support guarantees.
#4 Integrate.io
Type: ETL/ELT/Reverse ETL (Both) | Deployment: Cloud
Best for: Companies needing a low-code, all-in-one platform that handles MySQL ETL/ELT and reverse ETL with strong scheduling and governance.
Integrate.io offers a cloud-based visual pipeline builder with prebuilt connectors for MySQL and many other systems. Supports batch and near-real-time pipelines into warehouses and back into operational tools. Differentiates with reverse ETL capabilities and emphasis on ease-of-use—drag-and-drop components and built-in transformations.
Key Features
Low-code visual designer. Build ETL/ELT jobs without writing code. SQL pushdown available for performance.
Reverse ETL. Sync data out of MySQL or warehouses into CRMs and SaaS tools. Close the loop on operational analytics.
Hundreds of prebuilt connectors. Plus scheduling, monitoring, and alerts out of the box.
MySQL Integration Specifics
- Connection method: Native MySQL support with direct connections. Supports Google Cloud SQL for MySQL, SSH tunnels, and IP allowlisting.
- Sync modes: Full and incremental loads with support for near-real-time syncs. CDC capabilities vary by source configuration.
- Transformation: Both in-pipeline (graphical components) and SQL pushdown in the destination.
- Real-time: Near-real-time for many connectors. Typically minutes-level latency for MySQL pipelines.
Pricing (2026)
Subscription-based with volume and feature tiers:
- SMB plans: Starting in the low hundreds per user/month
- Enterprise: Custom pricing at higher tiers
Pros
- Intuitive UI that enables non-specialists to build MySQL-centric pipelines
- Supports ETL, ELT, and reverse ETL in one platform
- Validated for Google Cloud SQL and other managed MySQL offerings
Cons
- Can become expensive as data volumes, connectors, or users scale
- Advanced features and data modeling can introduce a learning curve
- Less suited for very complex, code-driven big data pipelines compared to Spark
Ideal for: Mid-market teams looking for a single SaaS platform to orchestrate MySQL ETL/ELT and reverse ETL with minimal coding.
Not ideal for: Highly cost-sensitive or deeply engineering-led teams building bespoke pipelines on open-source tools.
#5 Apache Spark
Type: ETL/ELT (Both) | Deployment: Self-hosted (on-prem/cloud) + Managed services (Databricks, EMR)
Best for: Data engineering teams that need large-scale, distributed processing with MySQL as a source/sink for batch and streaming jobs.
Apache Spark is a distributed data processing engine that connects to MySQL via JDBC. Read from or write to MySQL as part of large-scale ETL pipelines or streaming jobs. Spark excels when MySQL is one node in a much larger data ecosystem that includes files, warehouses, and data lakes.
Key Features
High-throughput distributed processing. Handle massive datasets in batch ETL. Scale horizontally across clusters.
Structured Streaming. Continuous pipelines with MySQL as a sink. Process data as it arrives.
Rich API ecosystem. SQL, DataFrames, MLlib for complex transformations and ML workflows.
MySQL Integration Specifics
- Connection method: JDBC with the MySQL driver. MySQL treated as a generic JDBC source/sink via connection URL and credentials.
- Sync modes: Custom-built by engineers. Full extracts, incremental loads using timestamp or key ranges, and CDC if combined with binlog readers or change tables outside Spark.
- Transformation: In-pipeline within Spark jobs (Scala, Python, SQL). Pushdown of certain SQL operations to the source when supported.
- Real-time: Yes, via Structured Streaming with MySQL as a sink. MySQL is typically not used as a streaming source directly.
Pricing (2026)
- Open-source core: Free. Costs come from infrastructure (Kubernetes, YARN, EMR, Databricks) and operational overhead.
- Managed platforms (Databricks, EMR): Charge primarily on compute (DBUs, vCore hours) plus storage. Often tens to hundreds of thousands annually at scale.
Pros
- Extremely flexible and powerful for complex, large-scale transformations
- Integrates MySQL into broader big data pipelines and ML workflows
- Open-source with a broad community and ecosystem
Cons
- Significant engineering and DevOps investment to operate reliably
- Overkill for simple MySQL replication or SMB data volumes
- Requires strong Spark expertise; non-technical users cannot self-serve
Ideal for: Larger data teams with engineering resources, leveraging MySQL within complex big data or ML pipelines on Spark.
Not ideal for: Small teams or business users who just need straightforward MySQL → warehouse or reporting syncs.
#6 Talend Open Studio
Type: ETL | Deployment: Self-hosted (desktop + on-prem runtime)
Best for: Teams that want a mature, open-source ETL designer for MySQL and other sources, with fine-grained job control.
Talend Open Studio (TOS) is a desktop-based ETL IDE that generates Java jobs. Includes many dedicated components for MySQL—tMysqlInput, tMysqlOutput, tMysqlConnection, and more. Suits organizations that prefer visual job design but want code-level control and on-prem execution.
Key Features
Rich MySQL component set. Read, write, bulk load, stored procedures, validation. Purpose-built for MySQL workflows.
Visual job designer. tMap, lookups, and reusable metadata repositories. Design complex jobs without writing raw code.
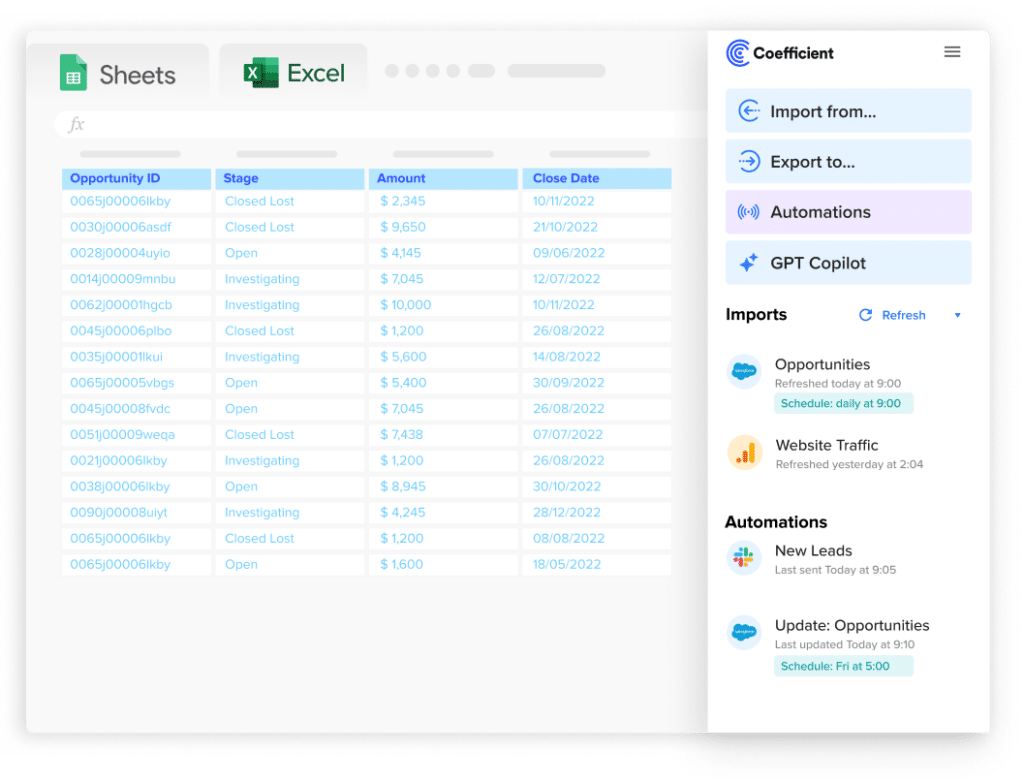
Stop exporting data manually. Sync data from your business systems into Google Sheets or Excel with Coefficient and set it on a refresh schedule.
Get Started
Generates Java code. Version control and custom extensions possible. Not locked into a proprietary runtime.
MySQL Integration Specifics
- Connection method: MySQL-specific components using standard JDBC under the hood. Connections configured via tMysqlConnection and reusable metadata.
- Sync modes: Typically batch ETL (full or incremental based on queries). CDC requires custom logic or additional Talend enterprise components.
- Transformation: In-pipeline using Talend components and tMap transformations.
- Real-time: Not natively streaming. Can approximate near-real-time with frequently scheduled jobs.
Pricing (2026)
- Talend Open Studio: Free and open-source. Costs come from infrastructure and developer time.
- Talend Data Fabric / Cloud: Subscription-based with full CDC and cloud orchestration. Quote-based pricing.
Pros
- Strong out-of-the-box MySQL support with many specialized components
- Visual design plus generated code suits mixed-code and low-code teams
- No license cost for Open Studio. Good for budget-conscious teams
Cons
- Desktop-centric workflow. Collaboration and CI/CD require extra tooling
- Lacks built-in modern cloud orchestration and observability
- CDC and advanced governance features mostly in paid Talend products
Ideal for: Small to mid-size teams comfortable running their own ETL jobs on-prem or in VMs, especially when MySQL is central.
Not ideal for: Organizations that want fully managed, cloud-native pipelines with built-in CDC and centralized monitoring.
#7 Hevo Data

Type: ETL/ELT (Both) | Deployment: Cloud
Best for: Startups and mid-sized businesses wanting no-code MySQL pipelines with real-time sync and SaaS-friendly pricing.
Hevo Data is a no-code, cloud-based data pipeline platform that supports MySQL as both source and destination. Real-time and batch pipelines with 150+ connectors and built-in transformations. Emphasizes ease-of-use and automation for teams that lack heavy data engineering resources.
Key Features
No-code pipeline builder. 150+ connectors with automatic schema handling. Build pipelines without writing code.
Real-time and batch pipelines. CDC capabilities included. Keep destination data fresh.
Built-in transformations and data quality checks. Clean data before it lands in your warehouse.
MySQL Integration Specifics
- Connection method: Native MySQL connectors using standard DB credentials. Secure networking options (tunnels, VPC connectivity) depending on deployment.
- Sync modes: Full loads, incremental syncs, and CDC depending on MySQL setup and connector configuration.
- Transformation: Both in-pipeline no-code transformations and ELT-style pushdown in supported destinations.
- Real-time: Yes, with near-real-time replication for supported MySQL sources.
Pricing (2026)
- Free tier: Up to 1 million events/rows per month with limited connectors
- Starter/Standard: ~$239/month for 5M rows. Additional rows ~$10+ per million
- Business/Enterprise: Custom pricing with HIPAA and higher SLAs
Pros
- Easy to adopt for teams without specialized data engineers
- Real-time support and CDC make it viable for operational analytics
- Transparent entry-level pricing and a usable free tier
Cons
- Can become more expensive as data volumes and low-latency requirements grow
- Less flexible than open-source tools for extremely custom pipelines
- Some connectors may have limitations on incremental extraction at very low latencies
Ideal for: SaaS startups and mid-market companies wanting MySQL-focused pipelines with minimal engineering overhead and real-time capabilities.
Not ideal for: Very large enterprises with extreme scale or highly customized data engineering needs.
#8 Stitch Data
Type: ELT | Deployment: Cloud
Best for: Teams needing a simple, cloud-based ELT service to replicate MySQL and other sources into a warehouse with predictable pricing.
Stitch Data is a cloud ELT platform (originally open-source Singer-based) that provides a MySQL connector among many others. Focuses on ease-of-use and transparent row-based pricing. Often used by smaller teams that want a straightforward way to centralize data into a warehouse without managing infrastructure.
Key Features
MySQL and SaaS connectors. Database and application connectors for warehouse-focused ELT.
Simple UI. Scheduling and monitoring for batch replications. Get running fast.
Webhooks and Connect API. Programmatic control for automation and custom workflows.
MySQL Integration Specifics
- Connection method: Standard database credentials and secure networking options, similar to other database connectors.
- Sync modes: Full and incremental batch syncs based on replication keys. Some CDC-like behavior via log-based replication in higher tiers.
- Transformation: ELT only. Data lands raw in the warehouse. Transformations handled downstream (dbt, SQL, etc.).
- Real-time: Primarily scheduled batch (every 5–60 minutes). Not designed for true streaming.
Pricing (2026)
- Standard: ~$100/month for up to 5–300 million rows/month. Single destination, 10 standard sources.
- Advanced: Up to 1 billion rows/month. More destinations, enterprise features (HIPAA, VPN, PrivateLink, extended log retention).
Pros
- Predictable, transparent pricing that scales with rows ingested
- Simple to set up and operate for common MySQL → warehouse scenarios
- Good fit for teams that want ELT without over-investing in tooling
Cons
- Less flexible and somewhat less robust than newer open-source alternatives for certain connectors
- Limited transformation capabilities. Requires additional tools for modeling
- Some users report connector reliability and support lagging versus competitors
Ideal for: Small to mid-size teams with straightforward MySQL → warehouse ELT needs and a preference for transparent row-based pricing.
Not ideal for: Organizations needing advanced CDC, complex transformations, or extensive customization.
#9 Matillion
Type: ELT (with ETL-like orchestration) | Deployment: Cloud + Self-hosted (cloud VMs + SaaS)
Best for: SQL-proficient data teams building warehouse-centric ELT, with MySQL as a source or secondary store, and needing strong orchestration and transformation.
Matillion is a cloud data integration platform that runs close to your warehouse (Snowflake, Redshift, BigQuery, etc.). Visual jobs compile down to SQL for pushdown transformations. Supports MySQL connectors and is widely used by teams that want to centralize ETL/ELT logic inside a SQL-first environment.
Key Features
Visual job designer with SQL pushdown. Build warehouse-centric transformations that execute in the destination for performance.
MySQL and database connectors. Extract and load into the warehouse with native support.
Orchestration and scheduling. Environment management for data pipelines. Production-ready workflows.
MySQL Integration Specifics
- Connection method: Native MySQL connectors configured within Matillion. DB credentials and network access from the Matillion instance to MySQL.
- Sync modes: Batch ELT with full and incremental loads via query- or key-based patterns. CDC requires external tooling or database features.
- Transformation: Primarily pushdown ELT in the target warehouse, with some in-pipeline orchestration logic within Matillion itself.
- Real-time: Designed for scheduled batch. Near-real-time requires tight scheduling and warehouse capacity.
Pricing (2026)
Credit-based model. 1 credit = 1 vCore-hour of processing. Pricing varies by plan:
- Basic / Advanced / Enterprise: Typical annual costs range from ~$20K–$35K/year in platform fees for small teams
- Additional costs: Warehouse compute and implementation services
Pros
- Strong for SQL-centric teams that want transformations executed in the warehouse
- Mature orchestration and scheduling features compared to lighter ELT tools
- Flexible pricing that scales with usage via credits
Cons
- Requires SQL proficiency. Not as accessible for purely business users
- Total cost can be significant once warehouse compute and implementation services are included
- Less attractive if MySQL is the primary analytical store rather than a source to a warehouse
Ideal for: Mid-market and enterprise data teams running modern warehouses, using MySQL primarily as a source, and comfortable working in SQL.
Not ideal for: Very small teams, organizations without a cloud warehouse, or non-technical stakeholders who need low-code MySQL-centric tooling.
Make the Right Choice for Your MySQL ETL Needs
Each tool serves a different purpose:
- Coefficient gets MySQL data into spreadsheets fast—no engineering required
- Fivetran delivers managed CDC with minimal maintenance
- Airbyte offers open-source flexibility for teams that want control
- Integrate.io covers ETL, ELT, and reverse ETL in one platform
- Apache Spark handles enterprise-scale distributed processing
- Talend Open Studio provides mature, free, visual ETL design
- Hevo Data brings no-code real-time sync to startups
- Stitch Data offers simple ELT with predictable pricing
- Matillion excels at SQL-heavy warehouse transformations
The right choice depends on your technical resources, scale requirements, and budget.
For teams that live in spreadsheets and need MySQL data fast, Coefficient eliminates the complexity. Pull live data into Google Sheets or Excel, set it on a refresh schedule, and get back to analysis.
Get started with Coefficient today.



