Overview
Data gives you the insights you need to make smart business decisions.
However, manually extracting volumes of business data from multiple sources, such as databases, XML sources, and spreadsheets offers a lot of time and resource challenges.
Manual data extraction can also result in incorrect information, leading to inaccurate reports, and potential misleading analytics conclusions that inhibit your decision-making.
You’ll need a way to seamlessly pull data from multiple sources and store them in a central location to correlate, analyze, and report the information efficiently.
This is where data ingestion tools come in handy.
Data ingestion tools simplify and streamline the extracting, storing, and reviewing of information for your business.
Read on to learn about the top 11 data ingestion tools to kick-off and supercharge your data strategy.
What are data ingestion tools?
Before diving into the nitty-gritty of data ingestion tools, let’s go over what data ingestion is first.
In simple terms, data ingestion is the process of transporting information from various sources to a storage medium where you can easily access, use, and analyze it.
Manual data ingestion would take too much time and effort since you’ll need to check multiple data sources (which would visualize your data in various formats).
Data ingestion tools can make the process easier by automating your data integration procedures from multiple sources.
Essentially, a data ingestion tool is software that can automatically extract data from various data sources. It then facilitates transferring the data streams into one storage location, making analysis and reporting easier.
11 popular data ingestion tools
Ideally, a reliable data ingestion tool should be easy-to-use, scalable, secure, and supports multiple data sources.
Below are some of the data ingestion tool top picks to help you assess and determine the one that best fits your needs.
1. Coefficient
Coefficient is a no-code Software-as-a-Service (SaaS) solution that connects your spreadsheets to your company systems easily.
The solution lets you sync your Google Sheets account to business systems such as HubSpot, Salesforce, Google Analytics, Looker, database, API, and data warehouse.
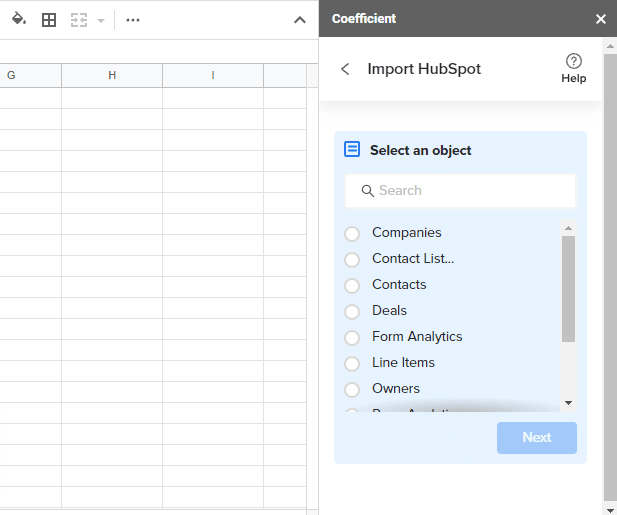
Coefficient makes data ingestion seamless by automatically importing all your data into a single place within Google Sheets.
It summarizes, filters, charts, creates pivot (or cloud pivot) tables, and easily integrates your datasets with other data.
This eliminates manual data ingestion, such as cutting and pasting CSV files, importing ranges, and other complex methods of combining your data and spreadsheets.
You can create custom reports and dashboards and query, alter, sync, manipulate, and join your data with little to no coding.
What makes Coefficient stand out is it offers an almost effortless data ingestion process. Connect your data source once and the solution automates the rest. This helps empower you to analyze and use your data in the most flexible and fastest ways.
2. Wavefront
Wavefront’s high-performance, cloud-hosted streaming analytics service lets you ingest, store, monitor, and visualize all forms of metric data.
The platform offers an impressive ability to scale to high data ingestion rates and query loads, reaching millions of data points for each second.
Wavefront allows you to extract data from over 200 services and sources, such as cloud service providers, big data services, DevOps tools, and others.
You can view your data through custom dashboards, perform forecasting and anomaly detection functions, and get problem value alerts (among others).
3. Precisely Connect
Precisely Connect (formerly Syncsort) provides a data integration solution through real-time ingestion or batch ingestion for advanced analytics, data migration, and machine learning.
The platform lets you access complex enterprise data from multiple sources and destinations for Change Data Capture (CDC) and Extract, Transform, Load (ELT) purposes.
You can seamlessly integrate data from legacy systems into next-gen data and cloud platforms using one solution.
Precisely Connect’s sources and target destinations include Relational Database Management Systems (RDMS), big data services, streaming platforms, and mainframe data.
The platform’s real-time data replication helps you ensure you can update data changes in data warehouses and analytics tools in real-time.
4. Apache NiFi
Apache NiFi is designed specifically to automate big data flows among software systems.
It leverages the ETL concept and provides low latency, high throughput, guaranteed delivery, and loss tolerance.
Apache NiFi’s data ingestion engine operates on a schemaless processing technology where each NiFi processor handles the interpretation of content of the data it receives.
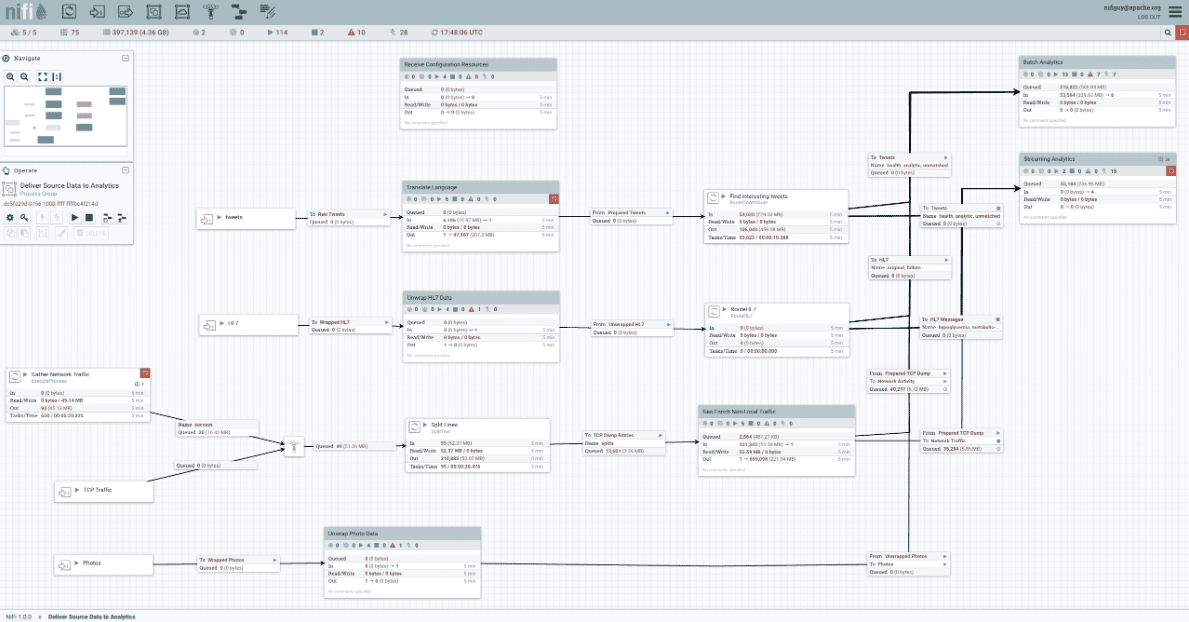
Let’s say processor X understands data format X and processor Y only understands format Y. You’ll need to convert data format X to format Y so processor Y can operate on format X and vice versa.
Apache NiFi can work as an individual tool or cluster (using its built-in clustering system).
5. Apache Kafka
The Apache Kafka big data ingestion software allows for high-performance data integration, streaming analytics, and data pipelines (among others).
The Apache-licensed, open-source software provides high throughput with low latency. It uses machines with as low as two milliseconds (2ms) latencies to deliver data at network limited throughput.
Apache Kafka can connect to external systems for data importing and exporting via Kafka Connect and is written in Java and Scala.
Since the platform is open source, you’ll get a wide array of community-fueled tools to get the extra functionalities you need.
6. Talend
Talend’s unified service, Talend Data Fabric, allows you to pull data from 1000 data sources. You can then connect them to your preferred destination, such as a cloud service, data warehouse, or database.
The cloud services and data warehouses the service supports include Google Cloud Platform, Amazon Web Services, Snowflake, Microsoft Azure, and Databricks.
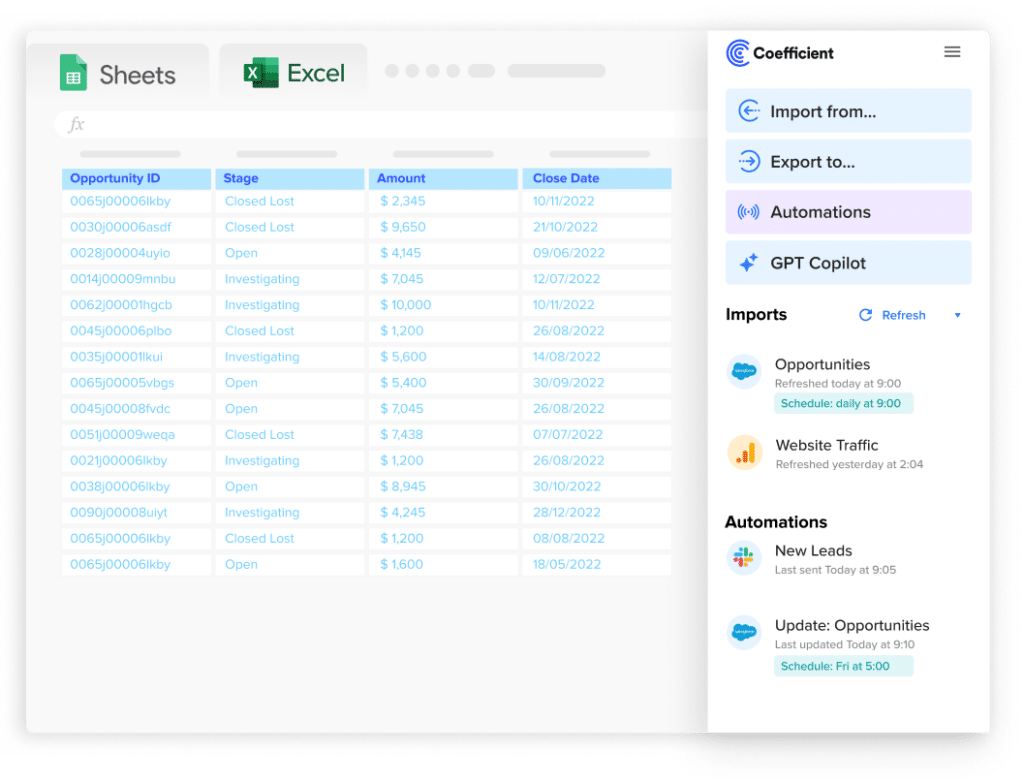
Stop exporting data manually. Sync data from your business systems into Google Sheets or Excel with Coefficient and set it on a refresh schedule.

Talend Data Fabric lets you build scalable and reusable pipelines via a drag-and-drop feature. It also provides data quality services for detecting errors and corrections.
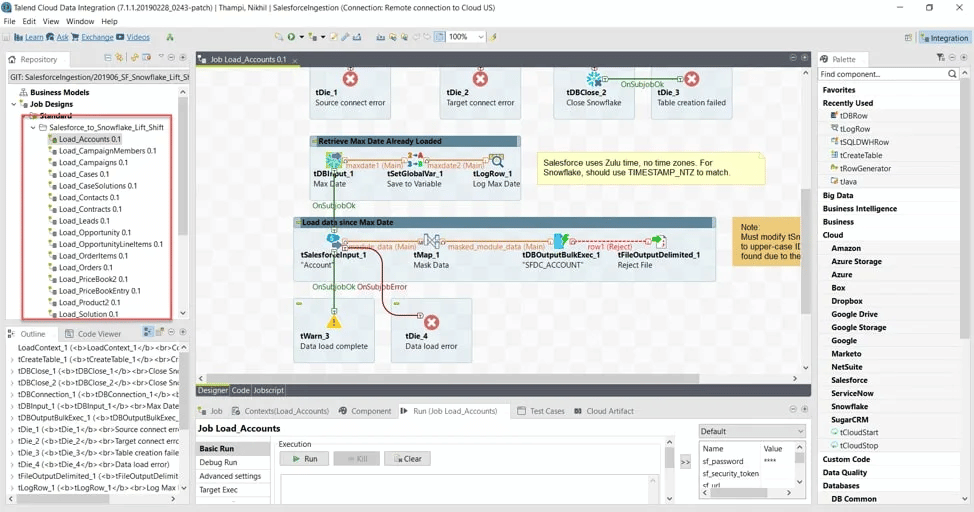
The service’s NoSQL database system allows you to streamline your data migration operations and easily transform unstructured data into JSON format.
7. Apache Flume
Like Apache Kafka, Apache Flume is one of Apache’s big data ingestion tools. The solution is designed mainly for ingesting data into a Hadoop Distributed File System (HDFS).
Apache Flume pulls, aggregates, and loads high volumes of your streaming data from various sources into HDFS.
While the platform is primarily used for log data loading to Hadoop, it supports other frameworks, such as Solr and Hbase.
Apache Flume is relatively simple compared to other big data ingestion tools. However, it still offers robust features, including fault tolerance functionalities with adjustable reliability mechanisms. Plus, the platform provides failover and recovery capabilities.
8. AirByte
AirByte’s open-source system is designed to help you implement integration pipelines quickly.
The data integration platform operates in your cloud and replicates your data from APIs, applications, and databases to data lakes, data warehouses, and other destinations.
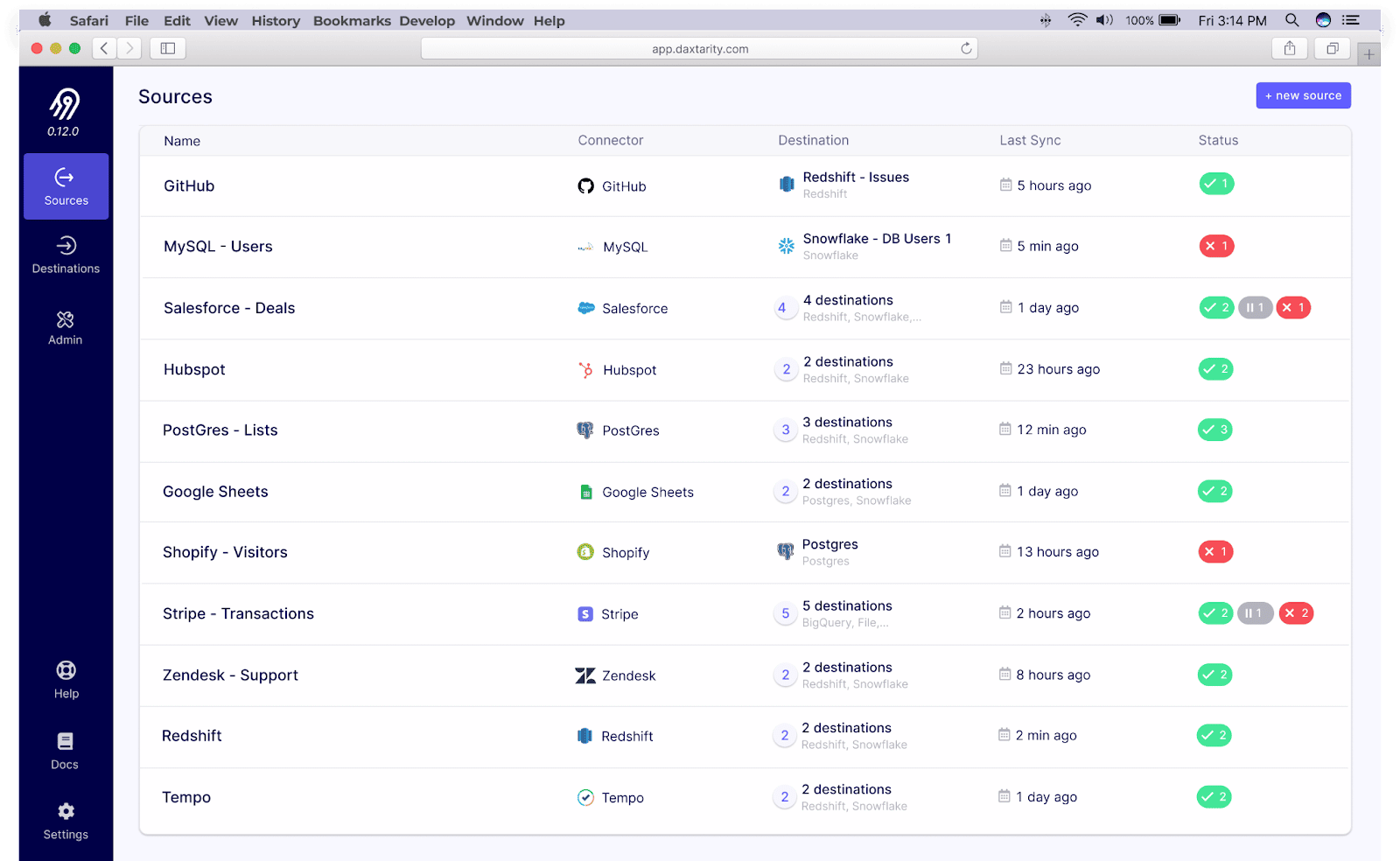
The platform allows access to more than 120 data connectors using a CDK to build custom connectors.
AirByte also offers log-based incremental replication features to help keep your data updated.
Data engineers and analysts can access raw and normalized data and conduct custom data transformation using a Data Building Tool (DBT) model.
9. Dropbase
Dropbase is a database service that helps you transform offline data, such as Excel, JSON, and CSV files, into live databases within a few steps.
It offers various processing methods, allowing you to efficiently perform data ingestion, loading, and transformation tasks.
Dropbase lets you process and format your data by editing, adding, re-ordering, and deleting process steps.
You can also write custom code or use a spreadsheet interface then import and export code. You can utilize Dropbase to load the data into a live database (or generate REST APIs) in one click.
10. Amazon Kinesis
Amazon Kinesis is a cloud-hosted, fully managed cloud data service that lets you extract, process, and analyze your data streams in real-time.
The solution can capture, store, and process data streams (via Kinesis Data Streams) and videos (through Kinesis Video Streams).
Amazon Kinesis captures and runs on terabytes of data per hour from thousands of data sources. Then, it loads the information to Amazon Web Services (AWS) data stores with the Kinesis Data Firehose.
11. Apache Sqoop
Apache Sqoop is a real-time, command-line-based data ingestion tool, mainly designed for transferring data streams between relational databases, Apache Hadoop, and other structured data stores.
Sqoop can make your life easier by providing Command Line Interface (CLI) to import and export your data.
Provide the necessary information, such as the database source, destination, authentication, and operations, and the platform automates the rest.
The platform uses Yet Another Resource Negotiator (YARN) framework to import and export data, providing a level of fault tolerance for Sqoop users.
Other key Apache Sqoop features include full and incremental load, connectors for major RDBMS, parallel import and export, and Kerberos security integration.
Find the right data ingestion tool for your business
A reliable data ingestion tool should streamline your data flows and give you an overall view of your business data.
Opt for a solution that best addresses your unique business needs and goals while speeding up the extraction of insights, reporting, and analysis of data.
Coefficient provides the simplest and fastest solution to do this, making your data ingestion process seamless and efficient.
Try Coefficient for free and experience it yourself.