Most enterprise data problems are not warehouse problems. They are last-mile problems.
Your data engineering team has done the hard work. They built the pipelines, defined the metrics, standardized the logic. Revenue means one thing. Churn means one thing. Every system feeds into a governed source of truth. The architecture is sound.
Then a finance analyst needs numbers for the board deck. They cannot wait three days for a data ticket to move. They do not write SQL. So they do what business users everywhere do: they go around the governed layer entirely. They pull a raw export, open it in the tool they know best and build their own version of the truth. The investment your data team made gets bypassed in minutes.
At enterprise scale, this is not one analyst making one decision. It is hundreds of people making the same workaround every week, across every department, every region, every business unit. Finance has its model. RevOps has theirs. Each regional lead maintains their own. The result is not a data silo. It is a silo ecosystem, and it grows faster than any governance policy can contain it.
This article covers why enterprise data silos are structurally different from the SMB version, the six patterns that create them at scale, and how to prevent each one without dismantling the workflows your business teams already depend on.
Why Enterprise Data Silos Are Harder to Solve
Three dynamics make the enterprise version of this problem qualitatively harder than it looks at smaller scale.
The integration gap is wider than most teams realize
MuleSoft’s 2025 Connectivity Benchmark put the average enterprise application count at 897 systems. Only 29% of those systems are integrated. Every unintegrated system is a potential workaround waiting to happen. Multiply that by the number of business users in the organization and the number of reports they produce each week, and the silo count scales faster than any central team can track.
Governance stops at the warehouse boundary
Data teams own the pipelines, the warehouse and the semantic layer. That governance perimeter is well-defined and well-maintained. But the moment data leaves those governed systems and lands in a local file or a disconnected tool, visibility disappears. What filters were applied. What formulas were added. Who shared it onward and with what modifications. None of that is visible to the team responsible for data quality.
Silos are organizational as much as technical
Different departments own different systems and have different incentives for sharing data. Finance protects its models. Sales protects its pipeline assumptions. Marketing protects its attribution logic. The silo is not just a missing integration. It is a political boundary, and a technical fix alone cannot dissolve it. Any prevention strategy has to work within the organizational reality, not assume it away.
Six Patterns That Create Enterprise Data Silos
Enterprise data silos do not appear randomly. They follow predictable patterns. Recognizing which pattern is active is the first step to preventing it.
The scheduled export chain
Data is exported from System A, reformatted in Tool B, pasted into Report C and emailed to a distribution list every Friday. Every step in that chain adds a delay and a new source of error. By the time the report reaches the executive who needs it, the underlying data has already moved on. The chain looks like a process. It is actually a series of disconnected snapshots.
The one-admin bottleneck
All meaningful data access flows through one analyst or one BI team. Everyone else waits for a ticket. The bottleneck is not a staffing problem. It is an access architecture problem. When self-service is not available, people build their own workarounds. Those workarounds become shadow data sources. Those shadow data sources become silos.
The department model problem
Finance builds its revenue model. RevOps builds theirs. Sales leadership maintains a third. Each uses slightly different assumptions, different cutoff dates, different definitions of the same metric. The CFO and the CRO arrive at every board meeting with different ARR numbers, and both are technically defensible from their own model. The organization cannot act on a number it cannot agree on.
The stale snapshot cycle
Reports are produced weekly or monthly. Between cycles, decisions are made from data that is already days or weeks old. The faster the business moves, the more costly the lag. Pipeline changes by the hour. A weekly reporting cycle is a competitive disadvantage when the market moves faster than the refresh schedule.
The governance bypass
This is the pattern most damaging at enterprise scale. A data engineering team invests months building a governed semantic layer: standardized metric definitions, validated dimensions, clean joins. Then a business user exports a raw table and builds their own version of the metric, because they need the data now and the governed path requires SQL they cannot write or a ticket they cannot wait for. The bypass happens not out of malice but out of necessity.
The session-based AI gap
Enterprises are investing in AI tools that query data warehouses using natural language. Most of those connections are session-based. The session ends, the connection ends, and the next query starts from a different snapshot. There is no persistent, governed pipeline. Each answer is potentially inconsistent with the last. The tool looks like a unified data layer. It is not.
How to Prevent Each Enterprise Data Silo Pattern Before It Forms
Each of the six patterns has a direct prevention strategy. None requires replacing the tools business teams use. All require changing how those tools connect to governed data.
Remove the export chain entirely
Every step in a scheduled export chain is a point of failure. The prevention is not to make the chain more efficient, it is to remove it. Connect business users directly to source systems through governed, live connections that refresh automatically. Coefficient connects 150+ enterprise systems, including Salesforce, Snowflake, NetSuite and HubSpot, to the tools business teams already work in. No export. No reformatting. No chain.
Dara Dickson at Ripple Labs on what direct access to live data changes:
“The tool is extremely helpful for pulling reports into Google Sheets which has saved me hours of manual work with as much data as I pull.”
— Dara Dickson, Ripple Labs — Salesforce AppExchange
Build self-service access on top of a shared governed connection
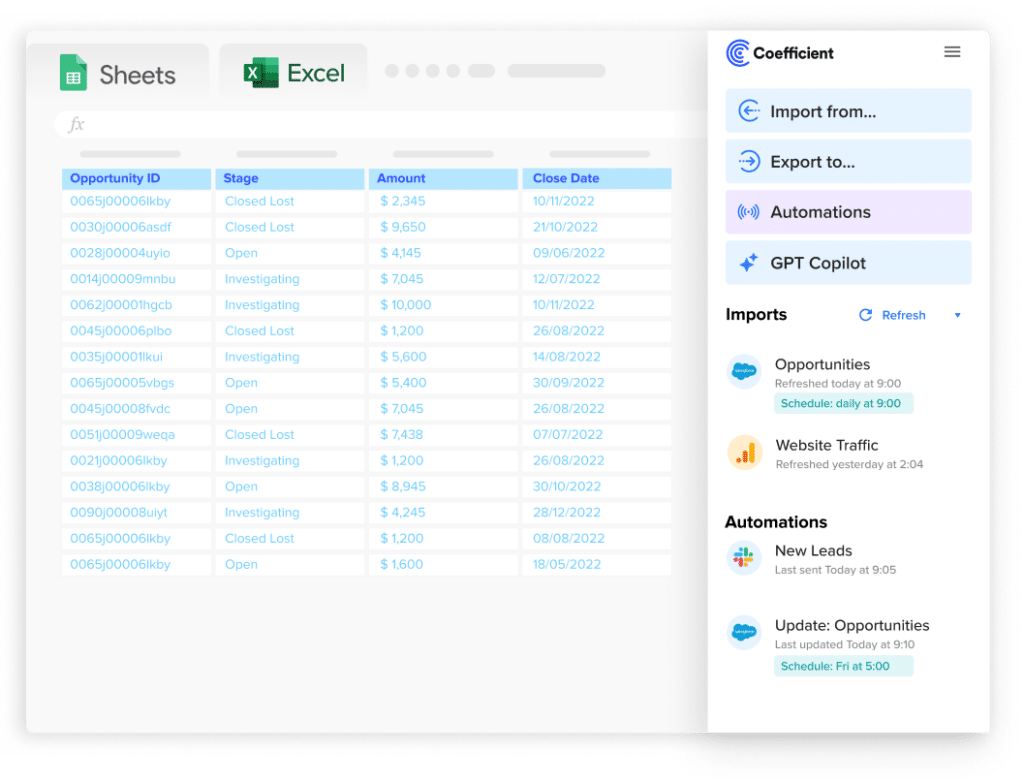
The one-admin bottleneck exists because sharing access safely is hard. Coefficient’s shared connection model lets one admin configure the connection to a source system once. The whole team pulls data through that single, secure connection without requiring the admin to field each request individually. Business users get the self-service access they need. IT retains control over credentials, permissions and data governance.
Philip Wiggins at TopDog Law on what this looks like for non-technical teams:
“It allows non-technical users to easily pull the data they need and analyze fresh data using tools they are already used to.”
— Philip Wiggins, TopDog Law — Salesforce AppExchange (5 stars)
Standardize on one live source, not one tool
The department model problem is a governance problem, not a tooling problem. The fix is not forcing every team onto a single platform. It is ensuring every team pulls from the same governed, live source, so the underlying data is identical even if each team’s analysis layer looks different.
Publishing a shared live dashboard from that canonical source using Coefficient’s Live Web Dashboard feature means every stakeholder, across finance, RevOps and sales leadership, sees the same number from the same source. The version debate ends because there is only one version.
Match refresh cadence to data velocity
Stale data is almost always a scheduling problem, not a technology problem. Pipeline data changes daily: set it to refresh daily or hourly. Financial close data moves monthly: a scheduled snapshot with an audit trail is the right cadence. Coefficient supports configurable refresh schedules per connection, so each source refreshes at the rate that matches how fast the underlying data actually moves.
Bring the governed data layer to the business user
The governance bypass happens because the gap between governed data and the people who need it is too wide to cross without technical skills. Closing that gap does not mean lowering governance standards. It means surfacing governed data through an interface business users can actually use.
| For organizations building out Snowflake’s Context Layer, the investment is in Semantic Views: standardized metric definitions, validated dimensions, governed joins. The goal is that Revenue means the same thing for every team and every tool. But if the only way to query those Semantic Views is SQL, most business users will bypass them entirely.Coefficient surfaces Snowflake Semantic Views through a visual Metrics and Dimensions picker inside Google Sheets and Excel. Business users browse available metrics, select what they need, and Coefficient generates the correct query automatically. No SQL required. No governance bypassed. The definitions the data team built stay intact end to end, from the warehouse to the report where the decision gets made. |
Mike Cosner at Florence Healthcare on gaining direct access to Snowflake data:
“Discovering that I could now write my own SQL queries from Snowflake, and pull new reports into Google Sheets has totally changed my role. Now I can pair with automation and AI tools to manage accounts more precisely and proactively.”
Stop exporting data manually. Sync data from your business systems into Google Sheets or Excel with Coefficient and set it on a refresh schedule.
Get Started
— Mike Cosner, Florence Healthcare — Salesforce AppExchange
The Semantic Views picker goes a step further: business users reach the same governed output without needing to know SQL at all.
Replace session-based AI with persistent governed pipelines
Session-based AI tools are useful for exploration. They are not a governed data layer. A Coefficient connection is persistent: once configured, it refreshes automatically on the schedule you set, maintains a consistent auditable data source and gives every stakeholder access to the same live feed. The answer your CEO sees on Monday morning is built from the same data as the analysis your analyst ran on Friday afternoon.
Governance Controls That Work at the Business User Layer
Avoiding enterprise data silos is not only about connection architecture. It requires governance controls that give data leaders visibility and control without creating the friction that drives workarounds in the first place.
Full visibility through an admin dashboard
Coefficient’s admin panel gives data leaders visibility into every connected source, every import, every refresh and every user across the organization. Who pulled what data and when. Which connections are active and which are failing. Where the highest-volume data requests are concentrated. Governance starts with visibility, and visibility starts here.
Shared connections with permission tiers
The data team controls the connection. Business users access data through it without being able to modify credentials or connection settings. Access scales without governance eroding. A new team member connects through the same governed source from day one, not through a personal workaround they set up themselves.
Auditable write-back operations
When teams push changes back to source systems through Coefficient’s write-back capability, every operation logs a status, a timestamp and a record ID. Every update is traceable. Auditors see the same data trail as the business. The tool stops being a governance blind spot and becomes part of the auditable record.
Colleen Fehm at Jun Group on the flexibility this enables:
“There is much more flexibility in the scheduled updates and imports compared to other options, in addition to a snapshot feature. Customer support has also been very quick to address questions and issues.”
— Colleen Fehm, Jun Group — Salesforce AppExchange (5 stars)
Schema-level permission inheritance
For organizations using Snowflake Semantic Views, Coefficient surfaces exactly what the data team has defined, nothing more. Schema-level permissions carry through from Snowflake into Coefficient’s interface. If a business user does not have access to a metric or dimension in Snowflake, they will not see it in the picker. The governance layer extends to where the work happens, rather than stopping at the warehouse boundary.
What This Looks Like When It Works
Nicole Looker at Rebuy Engine on what self-service access to governed data changes for an executive team:
“Our entire GTM team uses Coefficient to grab data from Salesforce and put it into Google Sheets as needed. Our exec team does not need to be in Salesforce to look at snapshots of data, and Coefficient lets us deliver the data they need in their preferred method. It is super easy to use, and the automations make it simple to set it and forget it so that our leadership team can get the information they need on schedule.”
— Nicole Looker, Rebuy Engine — Salesforce AppExchange
Executives get data in the format they prefer. The GTM team stops fielding ad hoc requests. The governed source stays intact throughout. That is the last-mile problem solved: not by changing how executives work, and not by forcing data through a tool they will not adopt, but by connecting the governed layer directly to the workflow where decisions get made.
Enterprise Data Silos Are a Last-Mile Problem
Enterprise data silos are not a sign that data engineering failed. They are a sign that governed data did not reach the people who needed it. The warehouse is clean. The semantic layer is defined. The pipelines run. But the analyst who needed numbers by Friday found a workaround, because the governed path was not accessible to them.
Avoiding enterprise data silos means closing that gap at every layer: the pipeline layer, the access layer and the interface layer. It means making governed data accessible to the business users who need it, on a cadence that matches how fast their work moves, with the visibility and controls the data team needs to maintain trust in the numbers.
Coefficient is not a standalone BI platform and requires Google Sheets or Excel as the working environment. For enterprises where business users work in spreadsheets and data teams work in the warehouse, it is built for the gap between them.
See how Coefficient fits your enterprise stack: coefficient.io/get-started


