Data silos are easy to describe in the abstract. They are harder to take seriously until you see what they cost in practice.
A retailer overstocks a warehouse because its inventory system never spoke to its e-commerce platform. A hospital repeats expensive diagnostic tests because one department’s records are invisible to another. A finance team presents the wrong ARR number to the board because three different models were built from three different exports of the same source data.
These are not hypotheticals. They are the predictable outcomes of disconnected data, playing out in businesses of every size and sector, every week.
This article covers real data silo examples across healthcare, retail, financial services and revenue operations — what happened, what it cost, and what the underlying pattern was in each case.
- How Big Is the Data Silo Problem?
- Example 1: Revenue Operations – The Board Meeting Number Problem
- Example 2: Retail – Inventory Failures from Disconnected Systems
- Example 3: Financial Services – Compliance Failures from Inconsistent Records
- Example 4: Healthcare – The NHS and Fragmented Patient Records
- Example 5: Operations – Equipment Failures from Disconnected Maintenance Data
- The Common Thread Across Every Example
- What Businesses Do to Prevent This
How Big Is the Data Silo Problem?
Before the examples, a sense of scale. DATAVERSITY’s 2024 Trends in Data Management survey found that 68% of organizations cite data silos as their top concern, up 7% from the previous year. That figure is rising, not falling, despite years of investment in data infrastructure.
The financial picture is similarly stark. IDC Market Research estimates companies lose 20% to 30% of revenue annually due to inefficiencies caused by data silos. Gartner puts the average annual cost of bad data — much of it caused by siloed, inconsistent records — at $12.9 million per organization. Forrester research puts the productivity cost at approximately 12 hours per employee per week spent searching for data trapped in disconnected systems.
Behind each of those figures is a specific failure pattern. The examples below show what those patterns look like in practice.
Example 1: Revenue Operations – The Board Meeting Number Problem
What happened
This is perhaps the most common enterprise data silo example, and it happens in companies of every size. Finance closes the books and produces an ARR number. RevOps has a pipeline report that implies a different figure. Sales leadership presents a forecast built from a model they maintain in isolation. All three are built from slightly different exports of the same source systems, pulled at different times, with different filters applied.
The CFO and the CRO arrive at the board meeting with different ARR numbers. Both are technically defensible from their own model. Neither is trusted. The board cannot act on a number the leadership team cannot agree on.
The cost
Beyond the immediate meeting dysfunction, the pattern compounds. Forrester research puts the time cost at approximately 12 hours per employee per week spent searching for data trapped in disconnected systems. For a revenue operations team of five, that is 60 person-hours per week, or roughly 3,000 hours per year, spent on reconciliation work rather than analysis.
IDC’s estimate — that companies lose 20% to 30% of revenue annually due to data silo inefficiencies — reflects this compounding pattern. The silo does not just slow a single meeting. It degrades every decision made from incomplete or inconsistent data.
The pattern
The department model problem: each team builds its own version of the truth from the same underlying source, on a different schedule, with different assumptions. The silo is not in the data. It is in the process of accessing and refreshing it.
Example 2: Retail – Inventory Failures from Disconnected Systems
What happened
A retailer plans its holiday season inventory based on projected demand. The projection is built from sales history, loyalty program data and e-voucher redemption patterns. But the e-voucher redemption data is tracked in a separate system that never feeds into the supply chain management platform. The demand model does not know what the redemption system knows. The forecast is wrong before the season starts.
This specific case is documented by Mobidev in their analysis of retail data silo patterns. The outcome: miscalculated inventory assumptions and surplus stock piling up in warehouses after the season.
A broader retail pattern
The same structural problem plays out across retail in different forms. A customer who shops frequently in physical stores and also purchases online is known to two different systems — the in-store POS and the e-commerce platform — that share no data. As Boomi’s analysis of retail data silos describes: “disjointed inventory data produces stock count inaccuracies, excessive overstocking, and stockouts.” Without centralized inventory visibility, retailers cannot optimize stock levels, coordinate replenishments or fulfill orders quickly.
The SKIMS case: what fixing it looks like
SKIMS, the apparel brand, faced this problem as it scaled rapidly. Marketing and operations data became fragmented across platforms, making it impossible to get a reliable view of e-commerce performance. The team consolidated over 60 data pipelines into a centralized warehouse. After the integration, e-commerce data refreshed automatically every 15 minutes, giving every team a near-real-time view across the business.
The pattern
System silos, where POS, e-commerce, loyalty, supply chain and warehouse management platforms are built and maintained independently. Each system is optimized for its own function but blind to what the others know. Decisions that span those systems — demand forecasting, inventory allocation, personalized marketing — are built on incomplete inputs.
Example 3: Financial Services – Compliance Failures from Inconsistent Records
What happened
In financial services, data silos do not just slow decisions. They create regulatory exposure. When risk, compliance and customer service departments operate with separate records, inconsistencies accumulate. As Data Ideology’s analysis of data silo impact in financial services documents: different departments may record and store the same data differently, leading to inconsistencies that result in regulatory non-compliance. Financial reports generated from different data sets create the conditions for regulatory scrutiny and, in worst cases, legal consequences.
Fraud detection: where timing is everything
In financial fraud detection, siloed systems create a specific and costly failure mode. Fraud signals in mobile banking cannot be linked to credit card anomalies when those systems do not share data in real time. Each channel sees its own slice. No channel sees the full pattern.
As EM360Tech notes in their February 2026 analysis: “Fraud detection lives or dies on timing. And in siloed financial systems, that timing often fails.” Banks and fintechs are responding with unified customer data platforms and real-time alerting systems that link fraud signals across channels and subsidiaries.
The pattern
Departmental silos in a regulated environment, where different business units operate from different records of the same customer or transaction. The cost is not just inefficiency. It is regulatory risk, audit exposure and fraud that goes undetected.
Example 4: Healthcare – The NHS and Fragmented Patient Records
What happened
For decades, patient data across England’s National Health Service has been held in disconnected systems: GP records stored at individual surgeries, hospital trust records maintained separately, mental health providers, community care teams and social care organizations each holding their own incompatible data. When a patient moves between providers, their records often do not follow.
The result, documented in both the Sudlow Review and the Darzi Report published in 2024, is a healthcare system operating with persistent information gaps. Clinicians make decisions without full visibility of a patient’s history. Diagnostic tests get repeated because one provider cannot see what another already ran. Care coordination breaks down at every handoff point.
As the UK Parliament’s House of Commons Library summarized in its 2024 briefing: “this fragmentation can cause challenges for people’s care as well as for health research.”
The cost
A study published in PMC analyzing NHS acute hospital data found that millions of patients transition between hospitals each year, but those hospitals use several different, incompatible health record systems with minimal coordination between them. The resulting fragmentation means clinical decisions are frequently made without the full picture.
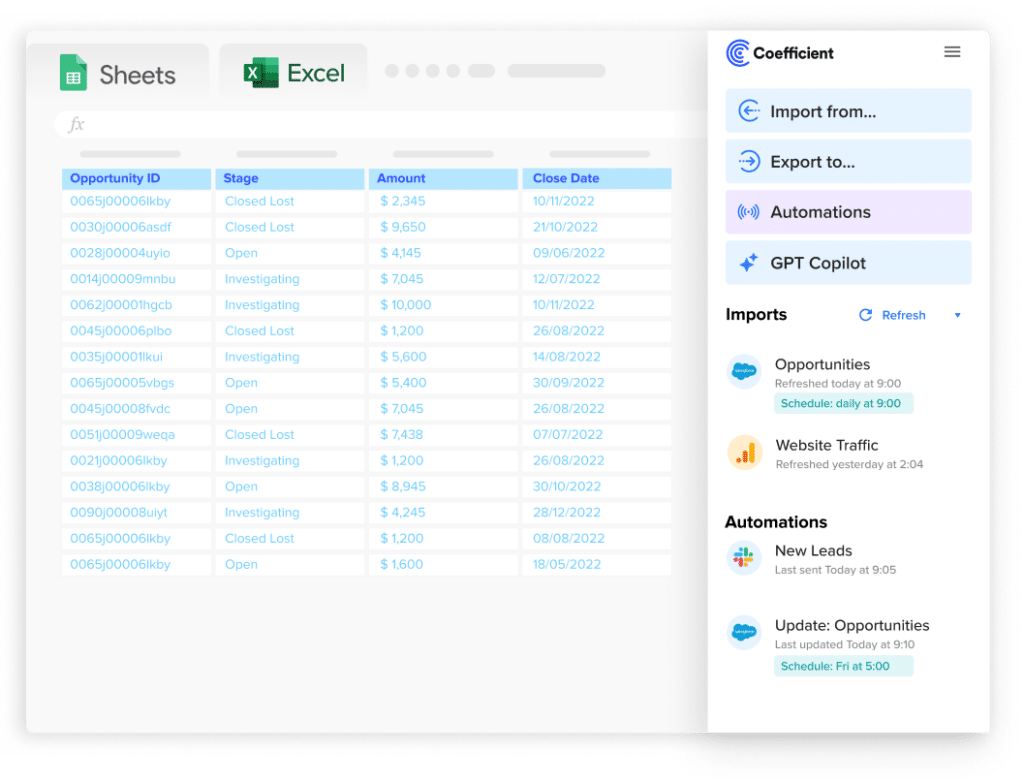
Stop exporting data manually. Sync data from your business systems into Google Sheets or Excel with Coefficient and set it on a refresh schedule.
Get Started
In one NHS trust in Lancashire, consolidating fragmented records into a shared care platform saved an estimated 10 to 15 minutes per patient in the hospital pharmacy department alone. Across an average of 3,000 admissions per month, that translates to savings equivalent to more than 750 working days and over £90,000 per year — in one department, in one trust.
The pattern
Institutional silos, where each organization or department owns and maintains its own data with no consistent mechanism to share it. The data exists. The problem is that it cannot travel with the person who needs it.
The UK government’s response is a legislative push for a Single Patient Record — a unified profile for every NHS patient, accessible to clinicians across the system. Implementation is targeted to begin for some specialties in 2027.
Example 5: Operations – Equipment Failures from Disconnected Maintenance Data
What happened
In asset-intensive industries like oil and gas, data silos between operational systems and maintenance platforms create a specific failure mode. Equipment condition data is captured by sensors and operational systems. But if that data does not flow automatically into the maintenance management platform, a minor equipment issue escalates undetected.
According to research cited by Dimension Software, a single hour of unplanned downtime in oil and gas can cost nearly $500,000. The average oil and gas operator loses approximately $149 million per year due to unplanned outages — with siloed operational data a documented contributor to this failure pattern.
The pattern
Operational silos, where sensor data, ERP systems, maintenance platforms and production scheduling tools are not connected. The data exists. The warning is in the system. But it never reaches the person who needs to act on it.
The Common Thread Across Every Example
These examples span healthcare, retail, financial services, revenue operations and industrial operations. The industries are different. The specific failure modes are different. The scale of cost is different. But the underlying pattern in every case is the same.
Data was collected. Data was stored. Data was used by the team that owned the system. But it never reached the team or the decision that needed it, when they needed it.
The NHS held patient data. It was not accessible to the clinician at the point of care. The retailer held e-voucher redemption data. It was not visible to the supply chain model. The finance team held accurate revenue figures. They were not the same figures RevOps was working from.
In every case, the silo was not a storage failure. It was a connectivity failure. The data existed. The connection did not.
What Businesses Do to Prevent This
The prevention strategies vary by industry and by where in the stack the silo forms. But the operational fix at the business user layer — the place where most revenue operations, finance and marketing silos form — follows a consistent pattern.
The most common source of data silos in business teams is not the warehouse. It is the export. Every CSV downloaded from a source system is a frozen copy, disconnected from the live data the moment it is created. When every team maintains its own export schedule, no two teams are working from the same truth at the same time.
Connecting source systems directly to the tools business teams use — with automated refresh schedules and shared connections — removes the export step and with it the primary mechanism by which most business-layer silos form.
| Coefficient connects 150+ business systems including Salesforce, HubSpot, Snowflake, NetSuite and QuickBooks directly to Google Sheets and Excel. Instead of exporting data and working from a frozen copy, teams pull live data on a schedule they control. Everyone working from the same import works from the same source. The board meeting number problem ends when there is only one number, coming from one live connection, visible to every stakeholder from the same shared dashboard. |
Coefficient is not a standalone BI platform and requires Google Sheets or Excel as the working environment. For business teams where silos form at the export layer — finance, RevOps, marketing ops — that is exactly where the fix needs to happen.
See how Coefficient eliminates the export layer: coefficient.io/get-started


