
Big data tools have reorganised themselves around a clear architecture in 2026. Most organisations running serious data workloads are converging on the same stack: a cloud data warehouse or lakehouse (Snowflake, Databricks or BigQuery) for storage and compute, a transformation layer (dbt), an orchestration layer (Apache Airflow or Prefect), and a visualisation layer (Power BI, Tableau or Looker). Apache Hadoop, the previous generation’s dominant framework, is in active decline as organisations migrate to cloud-native platforms.
This guide covers the tools in each layer, how they fit together, and what has changed in 2025 and 2026, including AI capabilities that are reshaping how data teams work.
| The modern data stack in one sentence: Ingest raw data via Fivetran or Airbyte → store and query in Snowflake, Databricks or BigQuery → transform with dbt → orchestrate with Airflow → visualise in Power BI, Tableau or Looker → surface to business users via dashboards or reports or spreadsheets with Coefficient. |
What Are Big Data Tools?
Big data tools are the platforms and frameworks used to ingest, store, process, transform and analyse data at scales that exceed what a single database or spreadsheet can handle. The category spans five layers, each with different tool categories serving distinct purposes.
| Layer | What it does | Leading tools in 2026 |
|---|---|---|
| Ingestion / Integration | Move data from source systems into a central storage layer | Fivetran, Airbyte, Stitch, Coefficient |
| Storage / Compute | Store data at scale and execute analytical queries | Snowflake, Databricks, BigQuery, Amazon Redshift |
| Transformation | Clean, model and structure raw data for analytics | dbt (data build tool), Spark, Snowpark |
| Orchestration | Schedule, monitor and manage data pipeline workflows | Apache Airflow, Prefect, Dagster |
| Visualisation | Present data as dashboards and reports for decision-making | Power BI, Tableau, Looker, Coefficient |
Storage and Compute: The Core of the Modern Stack
Snowflake
Best for: SQL-first analytics, BI reporting and organisations that want a managed cloud data warehouse without infrastructure overhead.

Snowflake separates compute and storage, meaning BI queries and ETL workloads run on independent virtual warehouses that do not compete for resources. Time Travel lets teams query data as it existed at any past point, one of the most practical data recovery features in the category. Snowflake integrates natively with dbt, Fivetran, Airbyte and all major BI tools. Snowflake Cortex AI adds LLM-powered SQL generation and natural language querying directly in the platform.
Key limitation: Consumption-based pricing can be unpredictable. Many organisations report bills 200 to 300% higher than budgeted when query optimisation is neglected. Not optimised for unstructured data or heavy ML workloads.
Pricing: Consumption-based. Credits from $1.50 to $4.00/hour depending on edition and commitment. See snowflake.com/pricing.
Databricks
Best for: Data engineering, machine learning, real-time streaming and organisations building AI-driven data products.
Databricks runs on Apache Spark and uses a lakehouse architecture via Delta Lake, combining data lake flexibility (structured, semi-structured and unstructured data) with data warehouse reliability (ACID transactions). MLflow manages the full ML lifecycle: experiment tracking, model packaging and deployment. Databricks AI/BI Genie (2025) adds natural language querying against Delta Lake tables.
Key limitation: Steeper learning curve than Snowflake. Requires Python, SQL or Scala expertise. Infrastructure configuration is more complex. Many organisations spend $50,000 to $200,000 or more annually even for moderate usage.
Pricing: Consumption-based (DBU credits). Contact sales or see databricks.com/product/pricing.
Google BigQuery
Best for: Google Cloud-native organisations, ad-hoc analytics at massive scale and pay-per-query cost models.
BigQuery is serverless with no infrastructure to manage. BigQuery ML allows data scientists to build and deploy ML models using SQL without moving data out of the warehouse. Native integration with Looker, Vertex AI and Google Workspace makes it the default for Google Cloud-committed organisations. Gemini AI adds natural language querying.
Key limitation: Pay-per-query pricing ($6.25/TB scanned on-demand) can be expensive for exploratory analysis on large tables without cost controls. Tighter Google Cloud lock-in than Snowflake or Databricks.
Pricing: $6.25/TB scanned (on-demand); flat-rate capacity from $2,400/month. See cloud.google.com/bigquery/pricing.
Amazon Redshift
Best for: AWS-native organisations with steady, predictable analytical workloads.Redshift is the incumbent data warehouse for the AWS ecosystem, with native integration to S3, SageMaker and the broader AWS data stack. Redshift Serverless adds pay-per-use flexibility for variable workloads. Reserved instance pricing makes it cost-predictable for consistent query loads.
Key limitation: Less flexible for multi-cloud organisations than Snowflake. Heavier administrative overhead than BigQuery for schema management. AWS-only unless using Redshift Spectrum.
Pricing: Serverless from $0.375/RPU hour; provisioned from $0.25/hour. See aws.amazon.com/redshift/pricing.
Transformation: dbt (data build tool)
dbt has become the standard for data transformation in the modern stack. It allows analytics engineers to write SQL transformation logic as version-controlled models that run directly in the data warehouse (Snowflake, Bigquery, Databricks or Redshift). dbt handles testing, documentation and lineage automatically. dbt Cloud (managed service, from $100/month per developer seat) adds scheduling, monitoring and collaboration. dbt Core is free and open source (self-hosted).
Why it matters for big data: dbt replaces ad-hoc SQL scripts and brittle spreadsheet-based transformations with governed, testable, documented transformation logic. Every metric definition becomes version-controlled code that the whole team can review and trust.
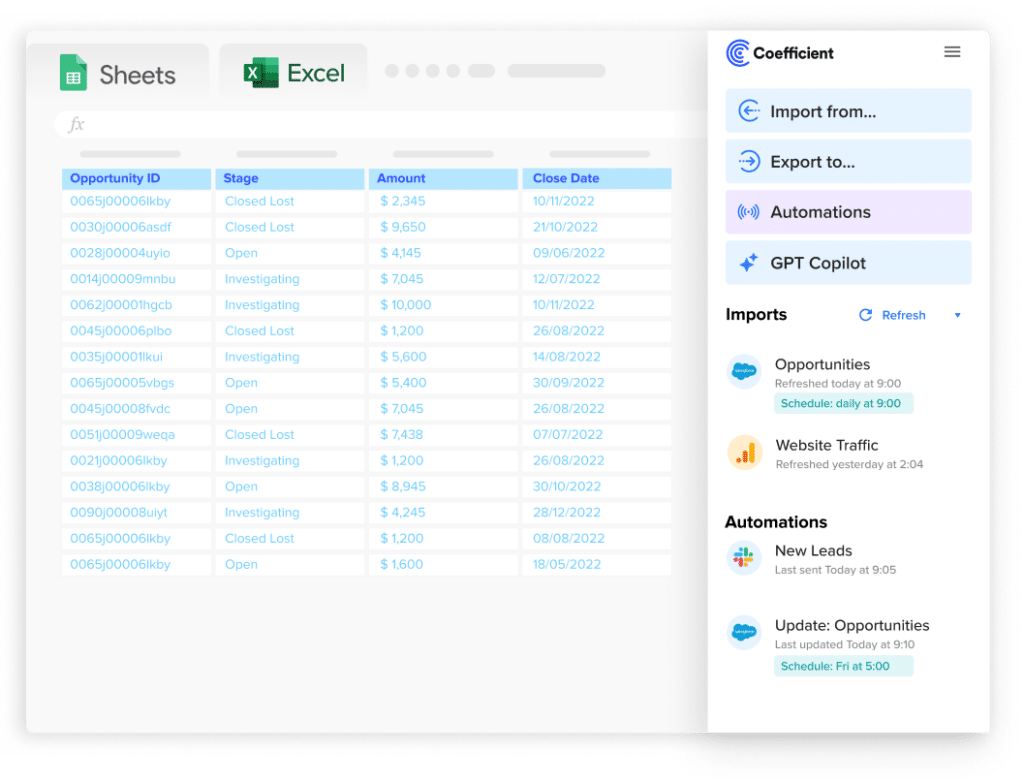
Stop exporting data manually. Sync data from your business systems into Google Sheets or Excel with Coefficient and set it on a refresh schedule.
Get Started
Processing: Apache Spark
Apache Spark remains the dominant engine for large-scale data processing, machine learning pipelines and streaming workloads. Most organisations use Spark through Databricks rather than managing their own Spark clusters. Spark’s in-memory processing runs analytics workloads far faster than Hadoop’s disk-based MapReduce model, which is why Hadoop adoption has declined sharply.
Key use cases: ETL pipelines on terabyte to petabyte datasets, streaming analytics from Kafka or Kinesis, ML model training on large feature sets, graph analytics. Not suitable for simple SQL reporting. Use Snowflake or BigQuery for that.
Orchestration: Apache Airflow
Apache Airflow is the most widely deployed workflow orchestrator in the modern data stack. Data engineers define pipelines as Directed Acyclic Graphs (DAGs) in Python, scheduling and monitoring every step from data ingestion through transformation to model deployment. Astronomer provides a managed Airflow service for teams that want the orchestration without the infrastructure overhead. Alternatives include Prefect (more Python-native, easier setup) and Dagster (asset-centric, stronger observability).
Ingestion: Fivetran, Airbyte and Stitch
Before data can be analysed it has to land in the warehouse. These tools handle the extraction and loading step:
| Tool | Model | Starting Price | Best For |
|---|---|---|---|
| Fivetran | Fully managed, 500+ connectors | From ~$0.001/MAR (per monthly active row) | Enterprise teams that want zero-maintenance pipelines |
| Airbyte | Open source (self-hosted free); Cloud from $2.50/connection/month | Free (self-hosted) | Technical teams that want open-source flexibility and cost control |
| Stitch | Managed, 130+ connectors | From $100/month | SMBs needing fast setup without infrastructure management |
The Last Mile: Bringing Big Data to Spreadsheets
The modern data stack terminates at a BI dashboard or a data warehouse query. Business users in finance, operations and RevOps often need the data one step further: in Google Sheets or Excel, where they can run their own analysis, build models and share results without learning a new platform.
Coefficient connects Google Sheets and Excel directly to the data layer (Snowflake, BigQuery, Redshift, Databricks and 100+ other systems) with scheduled auto-refresh and two-way sync. Finance teams pull live GL data from NetSuite into Excel for variance analysis. RevOps leads pull Salesforce pipeline into Sheets for forecasting. Data engineers pull from Snowflake into Sheets for ad-hoc analysis without writing a query. Vibe Reporting publishes live, shareable web dashboards from spreadsheet data via a plain-English description.
| “Coefficient automated everything. Instead of manually exporting data every day, I just sit back and watch the data update automatically.” Christian Budnik, FP&A Analyst, Solv |
How to Choose the Right Big Data Tools
| Your situation | Recommendation |
|---|---|
| SQL-first analytics team, BI-heavy workloads, want minimal infrastructure | Snowflake. SQL-native, managed, integrates with every BI tool. |
| Heavy ML/AI workloads, data engineering, real-time streaming | Databricks. Built on Spark, MLflow for ML lifecycle, Delta Lake for lakehouse. |
| Google Cloud-committed organisation, pay-per-query flexibility | BigQuery. Serverless, BigQuery ML, native Looker and Vertex AI integration. |
| AWS-native organisation, predictable steady-state workloads | Redshift. Native AWS integration, reserved instance cost predictability. |
| Need to transform and model raw warehouse data into governed metrics | dbt. The standard transformation layer for all four warehouses above. |
| Need to schedule and monitor complex multi-step data pipelines | Apache Airflow. The most widely deployed orchestrator in the modern stack. |
| Need to ingest data from SaaS sources into your warehouse | Fivetran (enterprise, managed) or Airbyte (open source, cost-effective). |
| Business users need live warehouse data in Google Sheets or Excel | Coefficient. Live connection from spreadsheets to Snowflake, BigQuery, Redshift and 100+ systems. |
Frequently Asked Questions
Is Hadoop still used in 2026?
Less than it was. Most new workloads go to Snowflake, Databricks or BigQuery. Hadoop persists in regulated industries with on-premises constraints (financial services, government, healthcare) and in organisations with legacy investments that have not yet migrated. For new projects, cloud-native platforms offer better performance, lower operational overhead and faster iteration without Hadoop’s infrastructure complexity.
What is the difference between Snowflake and Databricks?
Snowflake is a cloud data warehouse optimised for SQL analytics, BI reporting and structured data. It is SQL-native, easy to manage and integrates with every major BI tool. Databricks is a data lakehouse platform optimised for data engineering, machine learning and real-time streaming. It runs on Apache Spark, supports unstructured data and manages the full ML lifecycle. Many large organisations run both: Databricks for engineering and ML, Snowflake for SQL analytics and BI.
What is dbt and why does every data team use it?
dbt (data build tool) is a transformation framework that lets analytics engineers write SQL models as version-controlled code that runs directly in the data warehouse. It handles testing, documentation and lineage automatically. Before dbt, transformation logic lived in ad-hoc SQL scripts, spreadsheets or custom ETL tools, making it brittle and hard to maintain. dbt brought software engineering best practices (version control, testing, code review) to data transformation. dbt Cloud is the managed service. dbt Core is free and open source.
What big data tools have AI features in 2026?
Most major platforms added AI capabilities in 2025. Snowflake Cortex AI provides LLM-powered SQL generation and natural language querying. Databricks AI/BI Genie enables natural language querying against Delta Lake tables. BigQuery uses Gemini AI for natural language SQL generation. The trend is toward AI that generates and optimises SQL queries from plain-English prompts, reducing the technical barrier for analysts without eliminating the need for governed data models.
How do I connect big data warehouse data to Google Sheets?
Coefficient connects Google Sheets and Excel directly to Snowflake, BigQuery, Redshift and Databricks with a no-code connector and scheduled auto-refresh. Business users can import from any warehouse table or SQL query into their spreadsheet and set it to refresh automatically. This eliminates the manual CSV export cycle that most finance and ops teams rely on when they need warehouse data in a spreadsheet.
What is the modern data stack?
The modern data stack is the collection of cloud-native tools that most data teams assemble for the full data journey: Fivetran or Airbyte for ingestion, Snowflake or BigQuery for storage and compute, dbt for transformation, Airflow for orchestration and Power BI, Tableau or Looker for visualisation. The defining characteristic is that each layer is a best-in-class cloud service rather than a single monolithic platform. The trade-off is integration complexity: managing multiple tools and contracts adds overhead that all-in-one platforms like Databricks (which covers storage, processing and ML in one) aim to reduce.


