Despite the rise of cloud data warehouses and BI tools, activating data remains a challenge in modern enterprises. Business users still have a difficult time incorporating the data they need into their workflows and processes. But reverse ETL is combating these trends by providing actionable data directly to business users.
Reverse ETL integrates critical data into the systems that business users natively live in. This empowers SalesOps, RevOps, and other business users to harness the data in day-to-day tasks, analysis, and decision-making. Read on for a full overview of reverse ETL, including examples, solutions, and options for non-technical users.
The Problem: Company Data is Still Inaccessible
In today’s modern enterprise, data is more abundant than ever before. The average company employs 110 SaaS applications, creating a maze of competing systems for sales users and other business personnel to navigate.
The rise of cloud data warehouses has helped centralize this data in cloud-first, rapidly scalable data stacks. But even with cloud data stacks, company data still remains inaccessible for many business users, since they do not have the technical skills required to use the SQL-centric technology.
As a result, business users are in the same spot they were ten years ago. They must wait for the data team to provide them with insights. On top of that, the data team often operates with a backlog. This is a major reason why 63% of business users fail to receive insights on their required timeframes.
And even when data requests are fulfilled, they often come in the form of non-integrable BI dashboards. Business users cannot incorporate Looker or Tableau dashboards into workflows within their core systems, such as Salesforce and HubSpot. The data is locked in the dashboard, or not easy to extract.
No, what business users really need is the right data, at the right time, directly inside their native systems. That’s where reverse ETL comes in.
What is Reverse ETL?
Reverse ETL pushes data from a company’s centralized database directly into business systems. This empowers SalesOps and other business users to activate the data in their day-to-day roles.
Let’s take a closer look at how reverse ETL works, including how the related topics of ETL and ELT play in.
ETL (Extract, Transform, Load)
What does the ETL in reverse ETL stand for, anyway?
ETL is an acronym for Extract, Transform, Load. ETL was, for over four decades, the dominant data integration method.
With ETL, data integration occurs in this sequence of steps:
- Raw data is extracted from a source system (such as Salesforce or QuickBooks)
- The raw data is transformed on a processing server
- The transformed data is loaded into a target database
ETL pipelines, a.k.a. data connectors, connect a source system to a target database. The pipeline must transform, or structure, the data so it meets the requirements of the target database.
Otherwise, it’s like trying to fit a square peg into a round hole. The data just won’t “fit” if it’s not structured correctly for the database.
ELT (Extract, Load, Transform)
Although reverse ETL does not use the ELT protocol, it’s still important to understand ELT’s place in the modern data stack.
ELT stands for Extract, Load, Transform. ELT is a newer but increasingly popular data integration method in the past decade or so. An ELT pipeline executes this sequence of steps:
- Raw data is extracted from a source system
- The raw data is loaded directly into the cloud data warehouse
- The raw data is transformed inside the cloud data warehouse with SQL, Python, and other code
With the rise of cloud lakehouses and warehouses, transforming data before loading it in the database is no longer necessary. That’s why ELT can significantly speed up data integration, processing, and analysis across an organization. This explains the growth in ELT adoption recently.
Reverse ETL
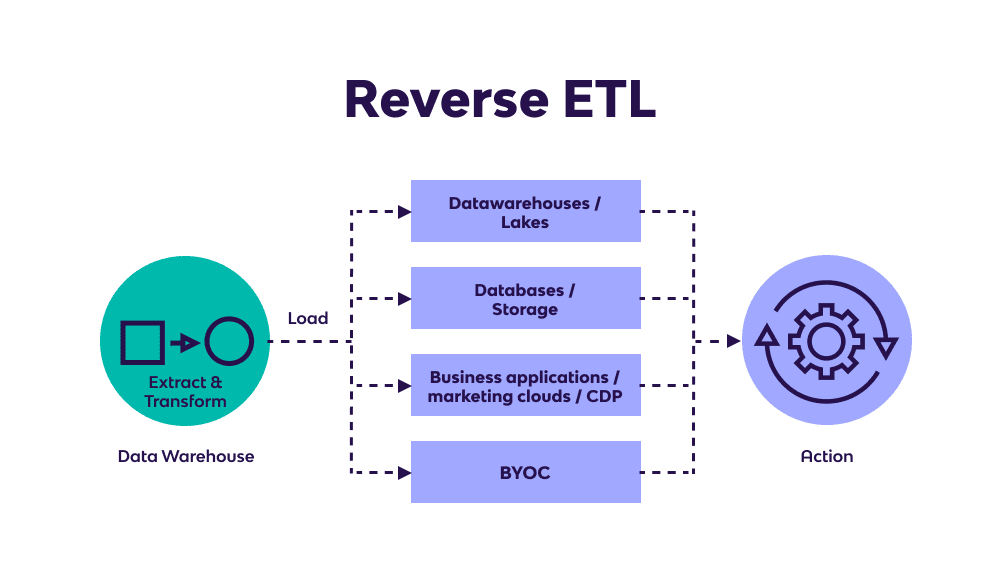
Reverse ETL is an emerging data integration paradigm, newer than both ETL and ELT. Although reverse ETL shares a name with ETL, it actually turns ETL on its head.
Instead of pulling data from a business system into a database, reverse ETL does the opposite: it pushes data from a database into a business system. In other words, the database is now the source system, and the business app is the target system.
Here’s the standard sequence of steps for reverse ETL:
- Raw data is extracted from a database (MySQL, Snowflake, Databricks)
- The raw data is transformed inside the database to meet the formatting requirements of the target business system (Salesforce, HubSpot)
- The transformed data is loaded into the target business system
Reverse ETL is almost the mirror image of ETL. However, data is extracted and transformed directly inside the database, without involving a secondary processing server. The data is then loaded into the target business system.
What Are the Benefits of Reverse ETL?
Reverse ETL equips SalesOps managers and other business users with the data they need, when they need it, during their day-to-day tasks. With reverse ETL, the data team becomes less of a bottleneck. Business users gain faster, more reliable access to the critical data they need to perform their roles.
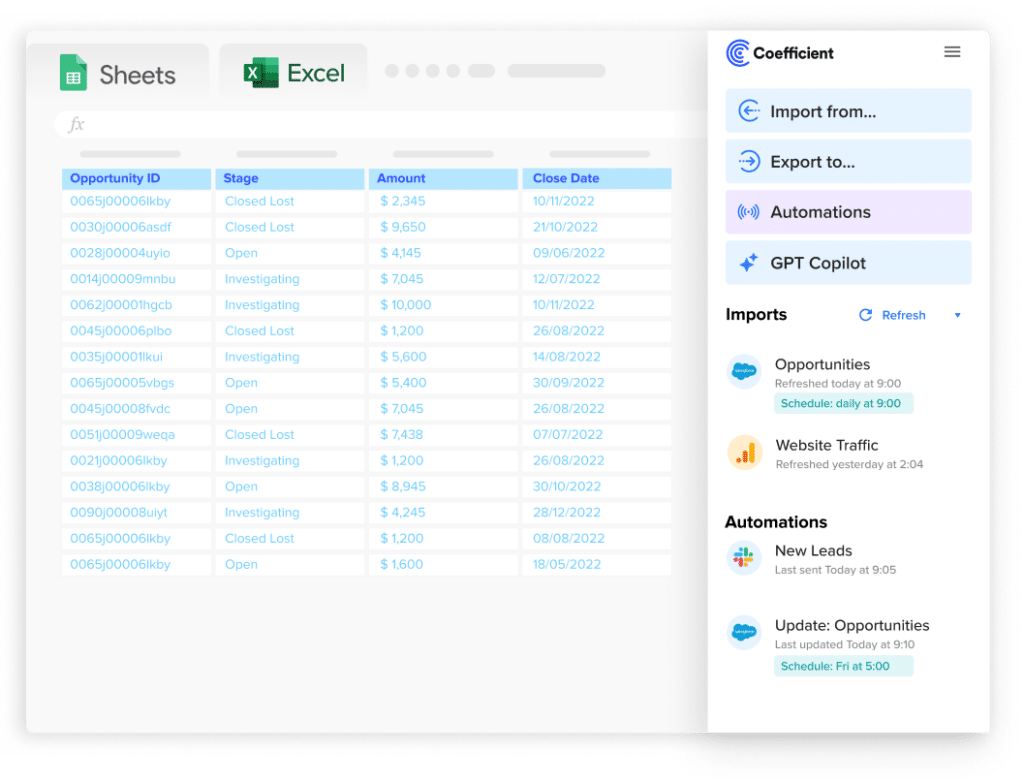
Stop exporting data manually. Sync data from your business systems into Google Sheets or Excel with Coefficient and set it on a refresh schedule.

Reverse ETL also allows business users to incorporate critical data directly into workflows, operations, and decision-making processes. This empowers workers to truly activate data in line-of-business processes, rather than stare at BI dashboards that do nothing to operationalize insights.
With reverse ETL, business users do not need to leave the business systems they feel most comfortable in, such as CRMs and spreadsheets. They can engage in self-service data analysis and accentuate business insights on their own, using the tools and analytical engines they understand.
From an organizational view, this helps business users activate the 73% of enterprise data that goes unused. They can close the modern data gap by becoming data and BI analysts in their own right. This makes companies more data-driven, and can enrich all business processes with self-service insights.
Reverse ETL: Examples + Use Cases
In recent years, we’ve seen some powerful examples of reverse ETL in action. Read the list below for some of our favorites:
- Sales – Enhancing sales enablement by pushing lead scoring data from Marketo, and LTV data from Tableau, into Salesforce
- Marketing – Building personalized marketing campaigns for a PLG SaaS by loading product data transformed by SQL queries in Snowflake into HubSpot
- Product – Optimizing customer onboarding process by sending user metrics derived from Amplitude data into Pendo
- Customer Success – Prioritizing support tickets by pushing account type data from MySQL into Zendesk
These reverse ETL use cases did anything and everything, from increasing sales, to improving lead conversions, to creating a seamless onboarding process, to clearing support backlogs.
The New Horizon: Spreadsheets + Reverse ETL
Reverse ETL allows business users to access company data quicker. However, business users can still encounter bottlenecks with reverse ETL, especially in regards to the data team.
The data team must expend time, and coding resources, to build reverse ETL pipelines. Once reverse ETL pipelines are built, the data will populate in a business system automatically. But if a user ever needs to change the data, they must file a request with the data team, and wait for pipeline updates.
That’s why some companies are turning to pre-built reverse ETL pipelines. Many SaaS ETL platforms now offer reverse ETL connectors as part of their core offerings. But this still leaves the data team in the driver’s seat. Business users must wait for the data team to set up these pipelines, even if they’re pre-built.
However, there’s a new way forward for reverse ETL that prioritizes business users. Increasingly, SalesOps and other users are turning to spreadsheets to import data from, and export data into, business systems.
With solutions such as Coefficient, business users can import live data into Google Sheets, run their logic/formulas on the data, and then push the data back into their business systems.
It’s reverse ETL – except the source system is a spreadsheet, rather than a database. As seen below, Coefficient enables you to export data from Google Sheets into business systems such as Salesforce.
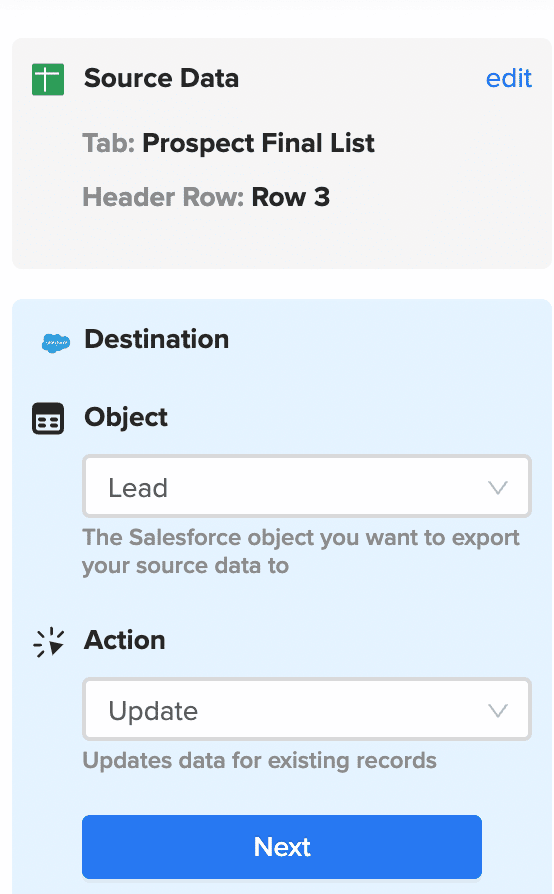
The combination of spreadsheets and reverse ETL closes the loop between business users, business systems, and business data. This allows SalesOps users to streamline data activation using their platform of choice: spreadsheets.
Reverse ETL: Activate Data Faster
Reverse ETL allows business users to access and operationalize data faster. By loading data directly into preferred applications, reverse ETL enhances and speeds up business processes. While dedicated SaaS reverse ETL platforms are emerging for data teams, solutions like Coefficient are actually bringing this powerful capability to business users through spreadsheets.
Now business users can create their own workflows, logics, and analytics flows directly from Google Sheets. This allows them to make faster, smarter decisions at every level of their job. Try Coefficient for free now to leverage the power of reverse ETL from a low-code spreadsheet environment.